Wenyan Li
Wenyan Li
Home
Publications
Projects
Posts
CV
Contact
Multimodal
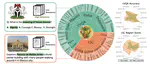
RAVENEA: A Benchmark for Multimodal Retrieval-Augmented Visual Culture Understanding
As vision-language models (VLMs) become increasingly integrated into daily life, the need for accurate visual culture understanding is …
Jiaang Li
,
Yifei Yuan
,
Wenyan Li
,
Mohammad Aliannejadi
,
Daniel Hershcovich
,
Anders Søgaard
,
Ivan Vulić
,
Wenxuan Zhang
,
Paul Pu Liang
,
Yang Deng
,
Serge Belongie
PDF
Cite
Code
Dataset
Project
Lost in Embeddings: Information Loss in Vision-Language Models
Vision–language models (VLMs) often process visual inputs through a pretrained vision encoder, followed by a projection into the …
Wenyan Li
,
Raphael Tang
,
Chengzu Li
,
Caiqi Zhang
,
Ivan Vulić
,
Anders Søgaard
PDF
Cite
Code
Words Worth a Thousand Pictures: Measuring and Understanding Perceptual Variability in Text-to-Image Generation
Diffusion models are the state of the art in text-to-image generation, but their perceptual variability remains understudied. In this …
Raphael Tang
,
Crystina Zhang
,
Lixinyu Xu
,
Yao Lu
,
Wenyan Li
,
Pontus Stenetorp
,
Jimmy Lin
,
Ferhan Ture
PDF
Cite
Website
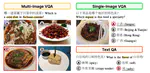
FoodieQA: A Multimodal Dataset for Fine-Grained Understanding of Chinese Food Culture
Food is a rich and varied dimension of cultural heritage, crucial to both individuals and social groups. To bridge the gap in the …
Wenyan Li
,
Xinyu Zhang
,
Jiaang Li
,
Qiwei Peng
,
Raphael Tang
,
Li Zhou
,
Weijia Zhang
,
Guimin Hu
,
Yifei Yuan
,
Anders Søgaard
,
Daniel Hershcovich
,
Desmond Elliott
PDF
Cite
Code
Dataset
Understanding Retrieval Robustness for Retrieval-Augmented Image Captioning
Recent advances in retrieval-augmented models for image captioning highlight the benefit of retrieving related captions for efficient, …
Wenyan Li
,
Jiaang Li
,
Rita Ramos
,
Raphael Tang
,
Desmond Elliott
PDF
Cite
Code
The Role of Data Curation in Image Captioning
Image captioning models are typically trained by treating all samples equally, neglecting to account for mismatched or otherwise …
Wenyan Li
,
Jonas F Lotz
,
Chen Qiu
,
Desmond Elliott
PDF
Cite
Code
Slides
MAP: Low-data Regime Multimodal Learning with Adapter-based Pre-training and Prompting
Pretrained vision-language (VL) models have shown impressive results on various multi-modal downstream tasks recently. Many of the …
Wenyan Li
,
Dong Li
,
Wanjing Li
,
Yuanjie Wang
,
Hai Jie
,
Yiran Zhong
PDF
Cite
Cite
×