Abstract
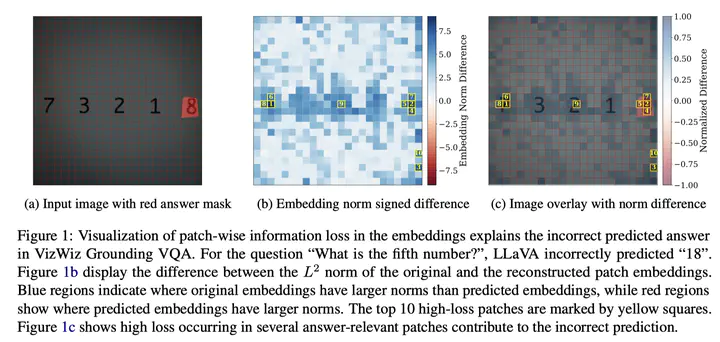
Vision–language models (VLMs) often process visual inputs through a pretrained vision encoder, followed by a projection into the language model’s embedding space via a connector component. While crucial for modality fusion, the potential information loss induced by this projection step and its direct impact on model capabilities remain understudied. We introduce two complementary approaches to examine and quantify this loss by analyzing the latent representation space. First, we evaluate semantic information preservation by analyzing changes in $k$-nearest neighbor relationships between image representations, before and after projection. Second, we directly measure information loss by reconstructing visual embeddings from the projected representation, localizing loss at an image patch level. Experiments reveal that connectors substantially distort the local geometry of visual representations, with k-nearest neighbors diverging by 40–60% post-projection, correlating with degradation in retrieval performance. The patch-level embedding reconstruction provides interpretable insights for model behavior on visually grounded question-answering tasks, finding that areas of high information loss reliably predict instances where models struggle.
Wenyan Li
My research interests include NLP, machine learning and speech recognition.