BLIP models
BLIPs
| BLIP | BLIP2 | |
|---|---|---|
| Image Encoder | updated | frozen |
| Text encoder/decoder | updated | frozen |
| Transformer | updated (BERT) | query transformer (Q-Former), including query embeddings (additional) |
| pre-training | pretraining with CapFilt | 2 stage pretraining with CapFilt |
BLIP
Main method:
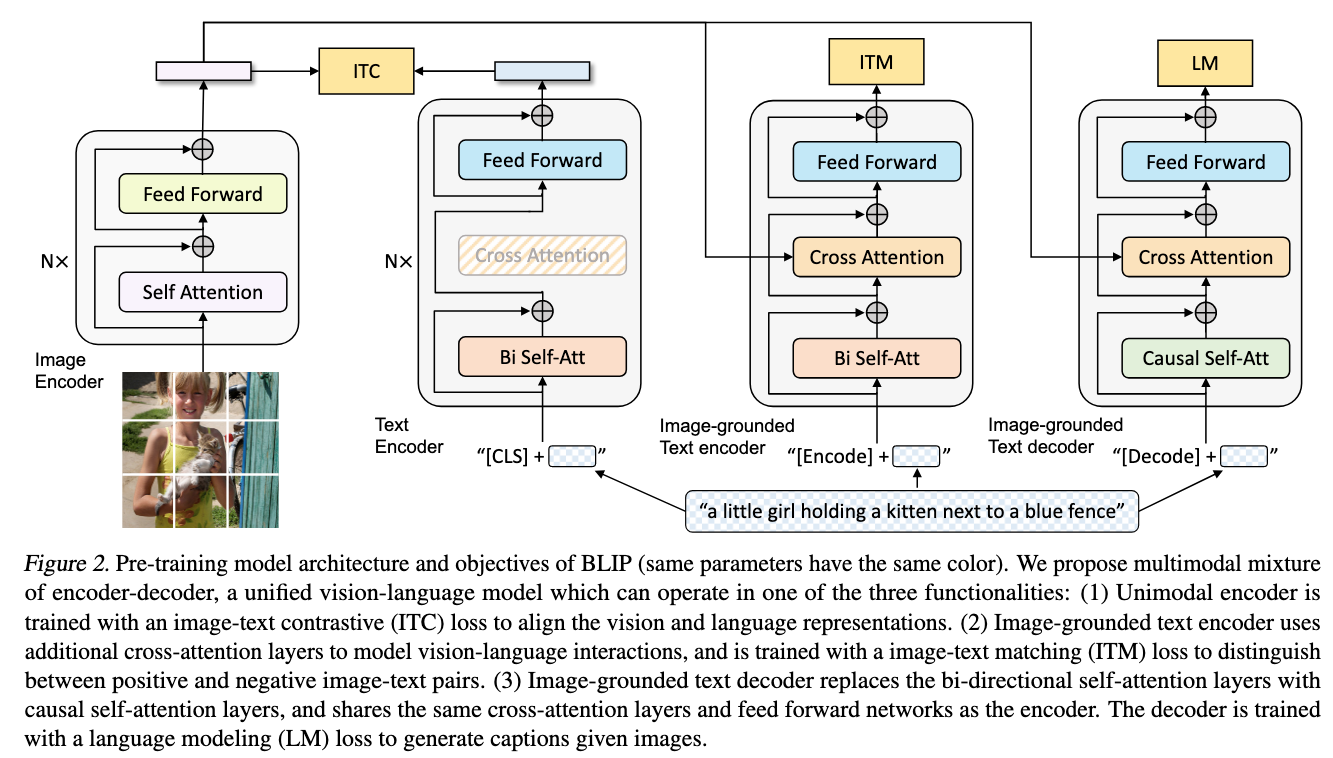
CapFilt: generate synthetic captions and filter to get(img,txt)pairsMultimodal mixture of Encoder-Decoder (MED)
MED
Model structure:
-
Image encoder
-
Text encoder — BERT(Bi SelfAttn, FF)
这一大块的模型变种共享除了self attention以外的参数
-
- additional cross attention ⇒ Image-grounded Text Encoder
- injects visual information with
[Encode]token
- injects visual information with
- additional cross attention ⇒ Image-grounded Text Encoder
-
- selfAttn + Casual SelfAttn⇒ Image-grounded Text Decoder
-
Three vision-language objectives:
分别与上面text相关模块变种负责的功能对应
- image text contrastive learning (ITC)
- image-text matching (ITM)
- image conditioned language modeling (ITG/LM)
CapFilt
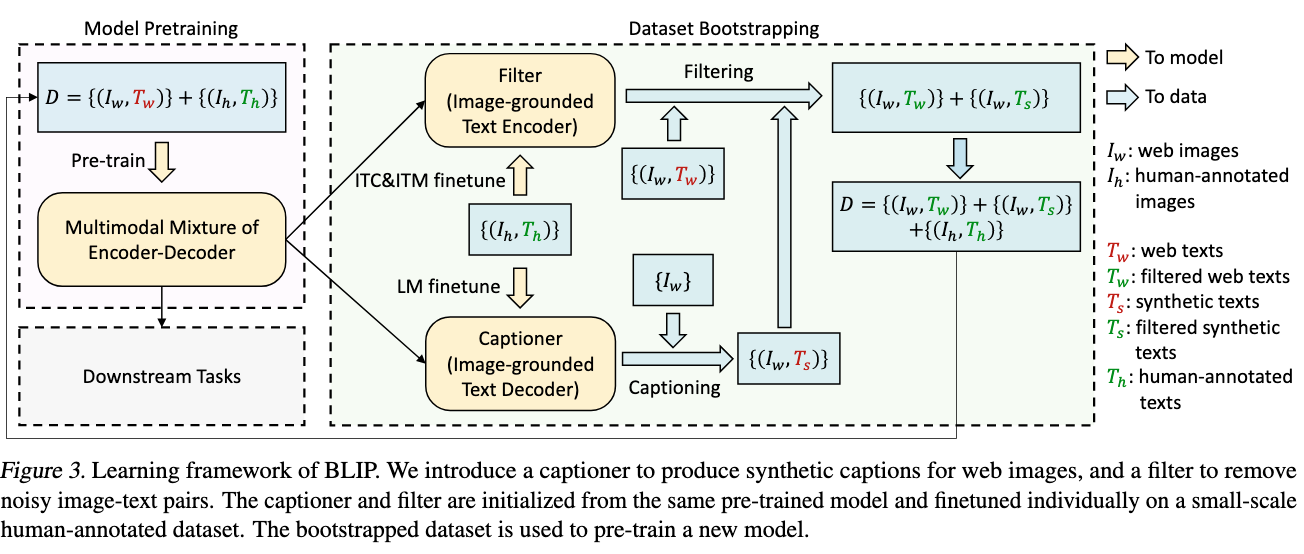
用COCO训练了一个captioning模型用来生成synthetic captions. Image-grounded text encoder用来过滤所生成的captions。
Experiments
- CapFilt 机制能够比较好地改善模型效果,对比网络抓取的caption,生成的caption效果更好。
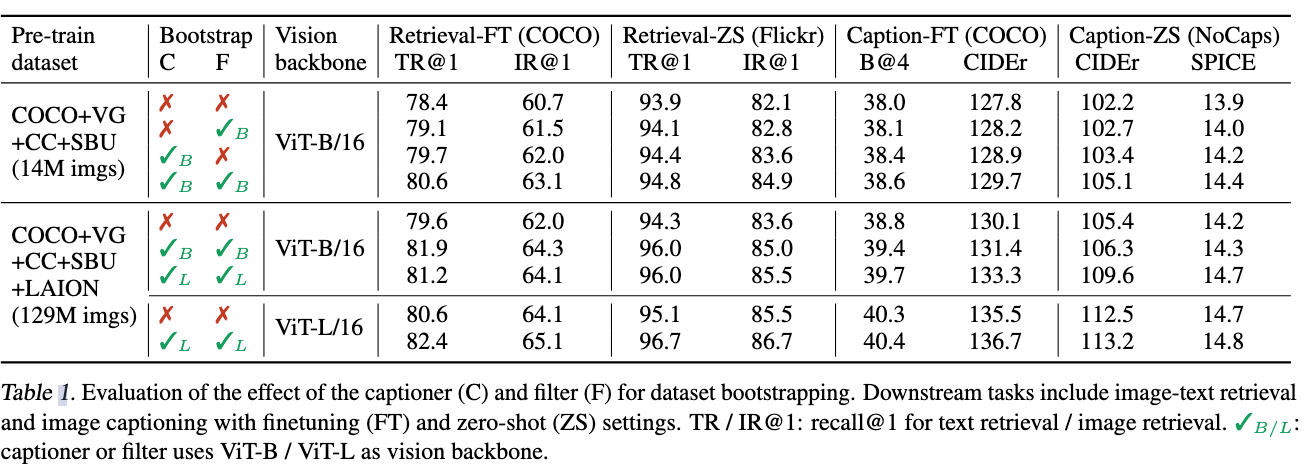
下游任务在VQA, retrieval, NLVR2, visual dialog以及captioning都做了evaluation。效果均超过baseline, 使用CAPFILT后效果在BLIP base上进一步提升。
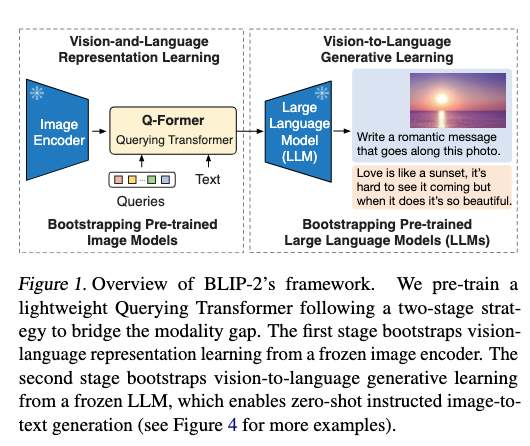
BLIP2
Main method:
- Image encoder 和 LLM 都是frozen的,只有
querying transformer参数更新。Q-former通过两个阶段的预训练起到一个两个模态间的桥梁作用,且轻量
Q-formerTraining involves two stages:-
- bootstrapping image encoder
-
- bootstrapping LLM
-
- Data: 129M images (COCO, VG, CC12M, SBU, LAION400M) + BLIP caption + CapFilt
- Submodules:
- Image encoder:
- LLM: decoder-only OPT; encoder-decoder instruction-trained FlanT5
Main contribution:
提出更轻量的VL模型,outperform Flamingo but 54x lighter.
Problems/challenges in previous models:
image-to-text generation lossare not sufficient to bridge modality gap from pretrained frozen models.- how to do better vision-language alignment? 如何实现多模态预训练模型之间的alignment?
Q-Former:
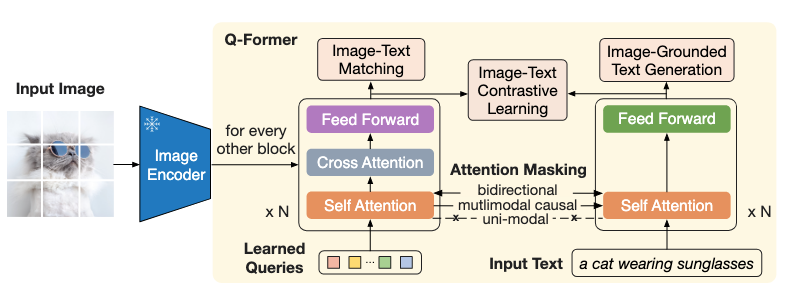
Model structure
-
two transformers: 这两个transformer同时也对应两个阶段的预训练
- image transformer: 从image encoder提取visual feature
- bottle neck for feature extraction (比直接使用frozen image encoder更轻量)
- text transformer:function as both a text encoder and a text decoder (既可以当encoder用也可以当decoder用)
- image transformer: 从image encoder提取visual feature
-
inputs: (image, text)
-
loss:
-
- image-text matching (ITM)— bidirectional
-
- image-text contrastive learning (ITC)— unimodal masking
-
- image-grounded text generation (ITG)— causal self-attention masking
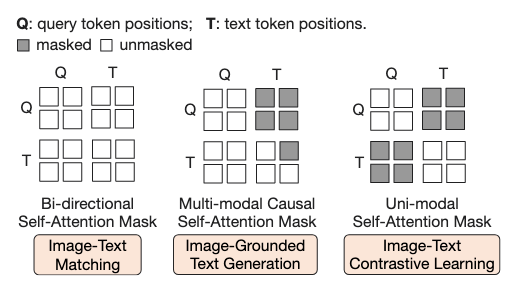
-
-
实现细节
- 自注意力层共享参数;
- 通过query embeddings和共享的自注意力层实现针对不同人物不同方式的图文交互
- query embedding (32x768)
- weights initialised from $BERT_{base}$ (188M #parameters)
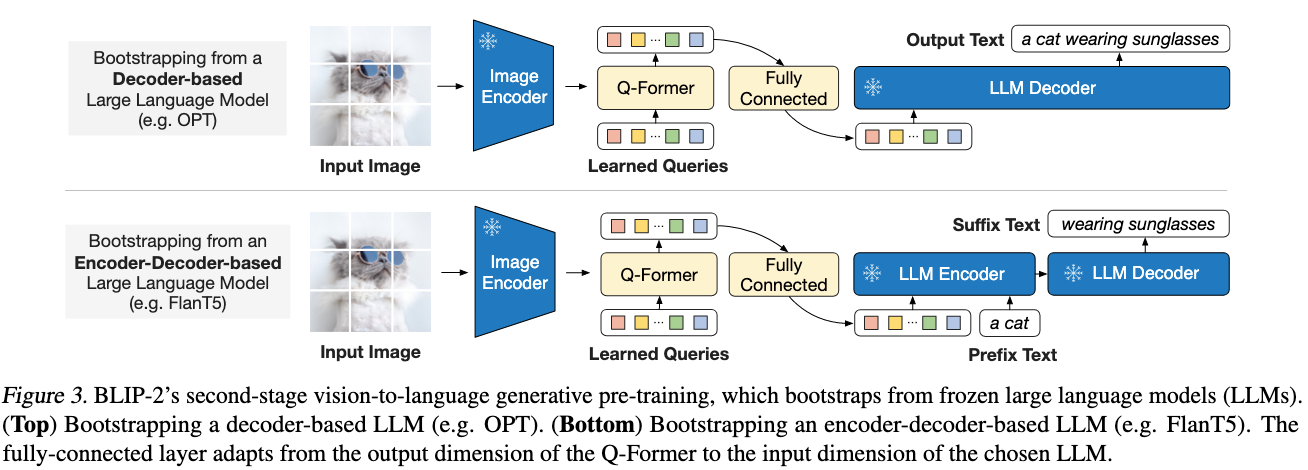
Learning stages
-
representation learning: 学习图像文本的相关性 alignment (frozen image encoder)
we perform vision-language representation learning which enforces the Q-Former to learn visual representation most relevant to the text.
-
generative learning: 有点像prompt- tuning,让学习到的图像feature适配LLM (frozen LLM)
这个适配直接通过FC层完成。LLM 的输入=
concat (FC(visual feature);text_embed)we perform vision-to-language generative learning by connecting the output of the Q-Former to a frozen LLM, and trains the Q-Former such that its output visual representation can be interpreted by the LLM.
Experiments
zero-shot VQA实验效果相当惊艳,秒杀一系列超大模型。Text-encoder部分使用FlanT5效果显著。
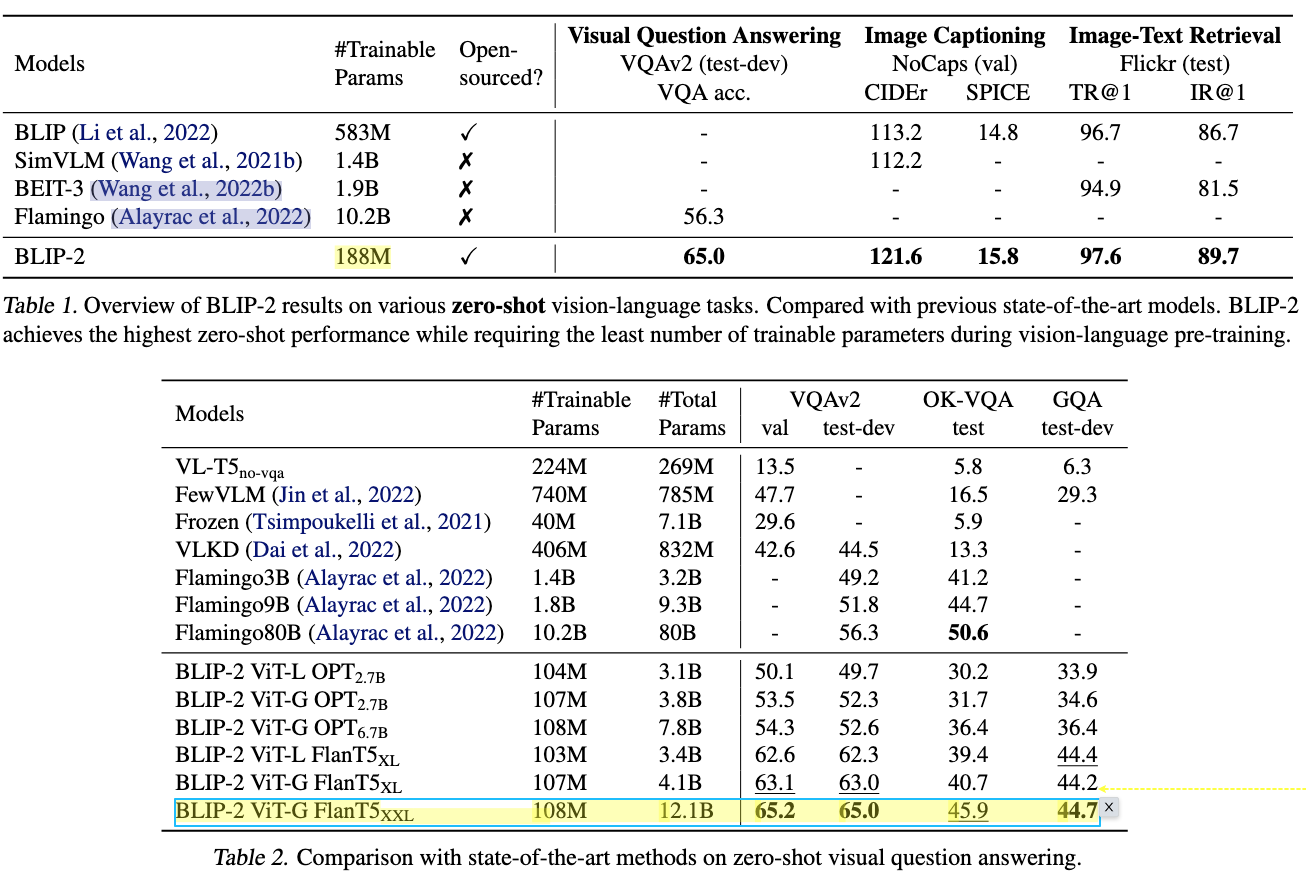
Image captioning
NoCaps zeroshot performance显著超越baseline,但是在COCO上finetune后的结果并没有提高。这里我认为是因为Image encoder和LLM都是超大模型,如果finetune image encoder反而会减弱它的能力(与之前的Frozen道理相同)。但是不太理解为什么这里作者要去对image encoder进行finetune,也没有给出只finetune Q-Former的对比实验。按道理来说还是一样去finetune Q-Former应该就能得到比较好的效果了。或者直接给出zero-shot结果。
Image-text retrieval
retrieval 的实验在BLIP的效果就已经比较饱和了。这里BLIP2在Flickr30k和COCO上都有进一步提升。同样这里BLIP2也是finetune Q-Former 和 image encoder。
Ablation
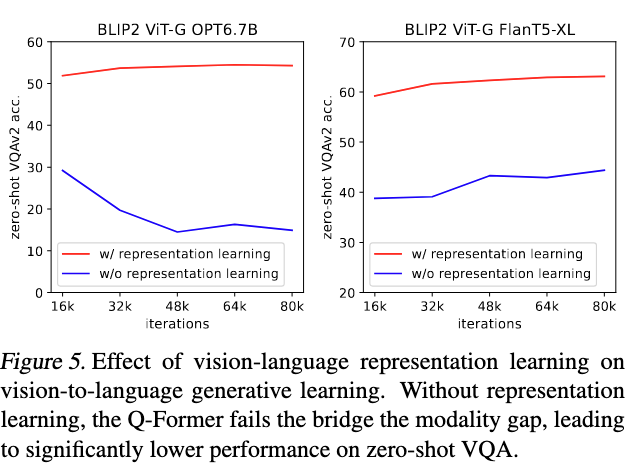
两阶段预训练效果显著,如果去掉第一部分的预训练,下游任务效果会显著下降。
Limitation
- “lack of in-context learning”
- “unsatisfactory results due to various reasons including inaccurate knowledge from the LLM, activating the incorrect reasoning path, or not having up-to-date information about new image content”
Wenyan Li
My research interests include NLP, machine learning and speech recognition.